Introduction
Brightcove Auto Captioning is a platform-level service that allows you to automatically generate captions for new or existing videos in 31 different languages (provided you have an audio track for the language specified). Like all speech-to-text services Auto Captioning is not 100% accurate, but it provides a quick and easy way to generate captions right in Video Cloud.
Video Cloud uses the following process to determine the source that will be used to generate the captions.
- If the video has a default audio track, that will be used as the captions source file (supported by default in the Media module)
- If the video has no default audio track but a master/mezzanine file exists, that will be used as the source file (supported by default in the Media module)
- If the video has no default audio track or master/mezzanine files, but audio tracks are specified in the Dynamic Ingest call, the specified audio track will be used (not yet supported in the Media module)
- If the video has no default audio track, no master/mezzanine files, and no audio track is specified, captions cannot be generated
Setup
The setup for Dynamic Ingest requests is the same, whether you are ingesting a video, images, audio tracks, WebVTT files, requesting auto captions, or all of these:
- Request URL
-
https://ingest.api.brightcove.com/v1/accounts/{{account_id}}/videos/{{video_id}}/ingest-requests - Authentication
- Authentication requires an access token passed as a
Bearertoken in anAuthorizationheader:Authorization: Bearer {access_token}To get access tokens, you will need client credentials (see below). For the process of obtaining an access token, see Get Access Tokens.
Note on S3
If your source files will be pulled from a protected S3 bucket, you will need to set a bucket policy to allow Video Cloud to access the files. See Using Dynamic Ingest with S3 for details.
Getting Credentials
To get a client_id and client_secret, you will need to
go to the OAuth UI and register this app:
These are the permissions you will need:
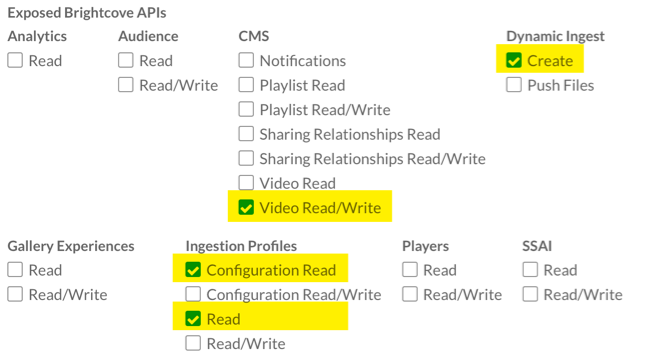
You can also get your credentials via CURL, Postman, or our online app - see:
If you are getting credentials directly from the API, these are the permissions you need:
[
"video-cloud/video/all",
"video-cloud/ingest-profiles/profile/read",
"video-cloud/ingest-profiles/account/read",
"video-cloud/upload-urls/read"
]Use cases
Here are some typical use cases
Create auto-captions for new ingestions or retranscoding
Request body
{
"master": {
"use_archived_master": true
},
"profile": "multi-platform-standard-static-with-mp4",
"transcriptions": [
{
"srclang": "EN-us",
"kind": "captions",
"label": "English",
"status": "published",
"default": true
}
],
"priority": "normal"
}Create auto-captions when ingesting an audio track
Request body
{
"audio_tracks": {
"merge_with_existing": true,
"masters": [
{
"language": "fr-FR",
"variant": "alternate",
"url": "https://support.brightcove.com/test-assets//audio/celtic_lullaby.m4a"
}
]
},
"transcriptions": [
{
"srclang": "fr-FR",
"kind": "captions",
"label": "french-FR",
"status": "published",
"default": false,
"input_audio_track": {
"language": "fr-FR",
"variant": "alternate"
}
}
]
}Create auto-captions for an existing video using the digital master
Request body
{
"transcriptions": [
{
"srclang": "fr-FR",
"kind": "captions",
"label": "french-FR",
"default": false
}
]
}Create auto-captions for an existing video defining the audio tracks
Request body
{
"transcriptions": [
{
"srclang": "en-US",
"kind": "captions",
"label": "english-EN",
"default": false,
"input_audio_track": {
"language": "en-US",
"variant": "main"
}
},
{
"srclang": "fr-FR",
"kind": "captions",
"label": "french-FR",
"default": false,
"input_audio_track": {
"language": "fr-FR",
"variant": "alternate"
}
}
]
}Request body fields for auto captions
The table below shows the request body fields for auto captions.
| Field | Type | Required | Description |
|---|---|---|---|
autodetect |
boolean | no |
true to auto-detect language from audio source. false to use srclang specifying the audio language.
|
default |
boolean | no |
If true, srclang will be ignored, and the main audio track will be used - language will be auto-detected.
|
input_audio_track |
object | no | For multiple audio tracks, defines the audio to extract the captions from. It is composed by language and variant (both required). |
kind |
string | no |
The kind of output to generate. Allowed values:
|
label |
string | no | Human readable label. Defaults to the BCP-47 style language code. |
srclang |
string | no | BCP-47 style language code for the text tracks (en-US, fr-FR, es-ES, etc.); see supported languages |
status |
string | no |
Indicates the actual situation of the caption, if it is published, draft.
|
url |
string | no |
The URL where a transcript file is located. Must be included in the kind is transcripts. Must not be included if the kind is captions.
|
use_dictionary |
boolean | no |
When true, apply the account autocaption dictionary to generated captions/transcripts when supported.
|
max_chars_per_line |
integer | no | Maximum characters per caption line when provided; must be between 25 and 60 inclusive when set. |
max_lines_per_cue |
integer | no | Maximum lines per caption cue when provided; must be 1 or 2 when set. |
diarization_mode |
string | no |
How speaker changes are represented when supported: hyphen, speaker_labels, or speaker_names.
|
enable_audio_tags |
boolean | no |
When true, include audio event tags in the output when supported.
|
allow_multilanguage_caption |
boolean | no |
When true, allow multilanguage caption behavior for this entry when supported.
|
ai_transparency_label |
string | no | Optional label for AI-generated text tracks (AI transparency). |
polished_transcription |
boolean | no |
When true, request a polished transcript style when supported.
|
translation_languages |
array | no |
Target languages for caption translation (and optional dubbing) after auto captions are generated for the source transcriptions entry. Each item is an object with srclang (BCP-47, required) and optional label, status (draft or published), dubbing (boolean), disable_voice_cloning (boolean), ai_transparency_label (string, label for translated captions when supported), and ai_transparency_label_dubbing (string, label for generated dubbed audio when supported). See Caption translation and dubbing and the Universal Translator documentation.
|
metadata_optimizer |
object | no |
Requests AI metadata enhancement in the same workflow as this transcriptions entry. Same fields as POST .../videos/{video_id}/ai/metadata-enhancement/{language}, including optional translation_request with only languages (BCP-47 array). On ingest, include translation_request only when skip_review and auto_translate are both true, and use explicit srclang on this entry (not autodetect: true). Must include language (BCP-47). See AI metadata enhancement at ingest and AI Metadata Optimizer.
|
audio_descriptions |
object | no |
Requests AI audio description in the same workflow as this transcriptions entry. Same body as POST .../videos/{video_id}/ai/audio-descriptions: required languages (array of BCP-47 strings) and optional ai_transparency_label (string, for generated descriptive audio tracks when supported). See Audio description at ingest and Audio Description.
|
input_audio_track fields
| Field | Type | Required | Description |
|---|---|---|---|
language |
string | yes | BCP-47 style language code for the text tracks (en-US, fr-FR, es-ES, etc.); see supported languages |
variant |
string | yes |
Specifies the variant to use:
|
Supported languages
Currently, auto captions are limited to the following languages
|
|